Prompt engineering became popular because it was the first part of AI work that felt accessible. You could open ChatGPT, type a better instruction, and get a noticeably better answer without learning infrastructure, deployment, or tests. Just you, the model, and a slightly more careful request.
I understand why that took off. Clear instructions beat vague ones. But the phrase starts to feel too small once AI moves from answering questions to doing work.
That shift is no longer theoretical. In 2025, SaaStr founder Jason Lemkin said Replit’s AI coding agent deleted production data during development, and, according to Lemkin, did so during a code freeze. Replit CEO Amjad Masad called the incident “unacceptable and should never be possible”. That story is dramatic, but the lesson is ordinary: once an AI can touch real systems, the risk is no longer just a bad answer. It is a bad action taken in a place where the action counts.
This is where the prompt becomes the wrong object to obsess over. You can tell an AI to be careful. But if it can still reach the production database, send the email, approve the refund, or change the record, the real question is not only what you told it. The real question is what kind of room you put it in.
That room is the harness: the working layer between the model and the world. It decides what the AI can see, which tools it can use, what it is allowed to change, what gets checked, what gets logged, and when a human has to approve the next step. Martin Fowler and Birgitta Boeckeler call this harness engineering.
The boundary matters. A policy, editor, or team habit is not part of the harness just because it exists. It becomes part of the harness when the AI runtime can actually use it as a rule, permission, tool, check, log, memory, or approval gate.
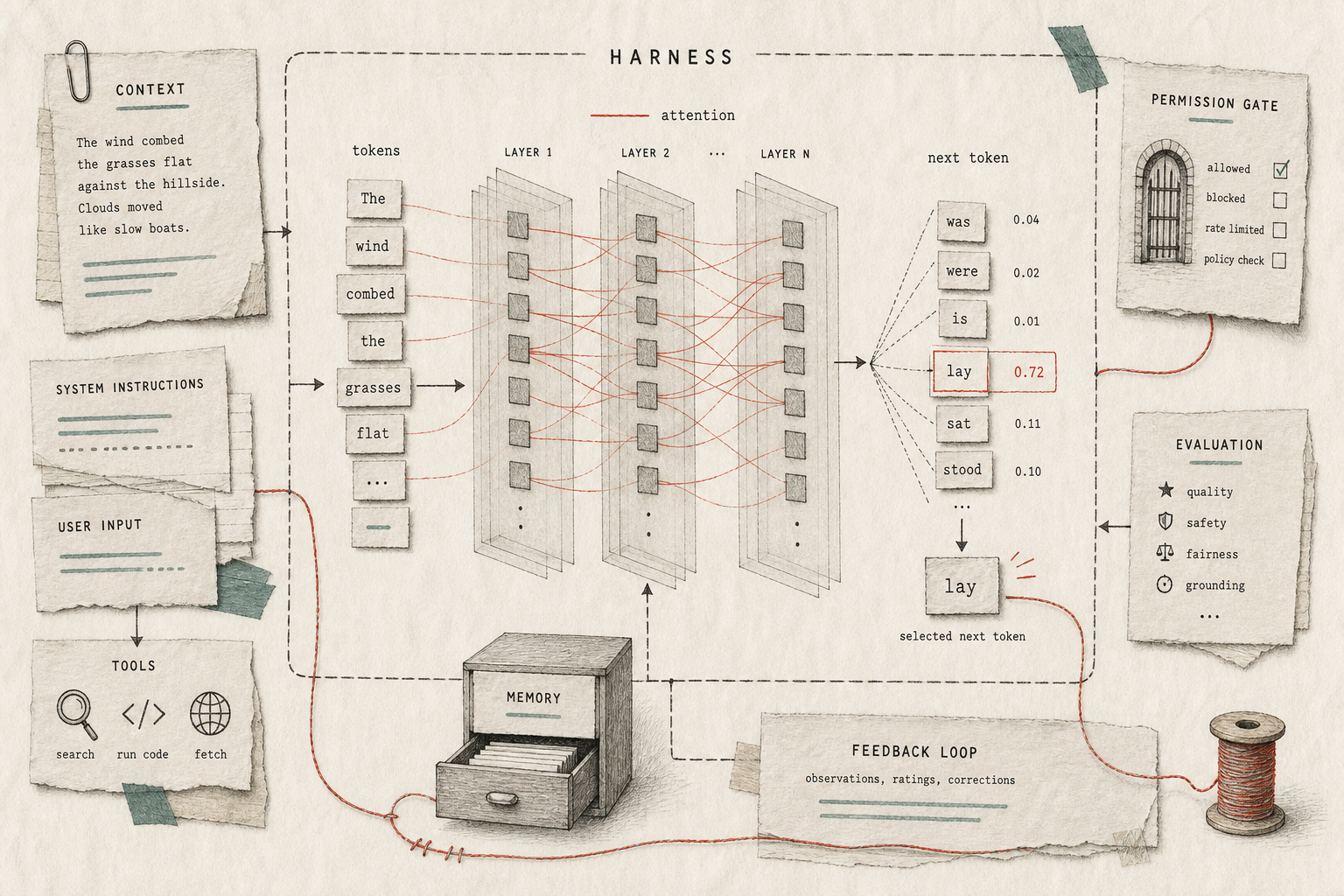
Figure 1. A useful AI product is not just a prompt going into a model. It is context, instructions, tools, permissions, memory, evaluation, and feedback wrapped around a model that predicts the next token one step at a time.
Less magical than clever prompting, yes. Also much closer to the work.
The instruction is not the system
Imagine asking a new assistant to help with your work.
You could say, “Be careful with customer data.” Maybe that helps a little. I would still rather give the assistant access only to the files it needs, block sensitive exports, log what it opened, and require approval before anything leaves the company.
The email example is even simpler. If the assistant can draft but not send, you do not need to trust a sentence in the prompt as much. The button is simply not available to the model.
Same with research. “Use reliable sources” sounds responsible, but it leaves the hard part inside the model’s judgment. Connecting the assistant only to approved sources, requiring links for factual claims, and flagging unsupported claims gives you something sturdier than vibes.
The prompt asks for behaviour. The harness changes the conditions under which behaviour happens.
Fowler and Boeckeler describe harness engineering as the work around the model that increases trust in an agent’s output. HumanLayer puts the same idea in more runtime-shaped language: the harness is the agent’s configuration surface, the parts that let the model interact with its environment. The model matters, obviously. But a good model behind the wrong interface can still do bad work very quickly.
Agents are different from chatbots
The word “agent” gets thrown around too much, but the useful distinction is simple enough: chatbots mostly respond; agents can act.
The action can be small: searching a document, calling a tool, editing a file, creating a calendar event, drafting a reply, or pulling data from another system.
It can also be risky. The same basic loop can send a message, change a record, delete a file, make a purchase, touch production systems, or access private information.
The moment an AI can act, the setup around it starts to matter more than the wording of the prompt. The failure mode is no longer just “the answer was wrong.” The failure mode becomes “the AI did something wrong in a place where wrong actions have consequences.”
Prompt engineering feels incomplete because it stares at the sentence we give the model and says much less about the room we put the model in.
What a harness looks like in normal work
Do not picture a giant platform first. In practice, the harness is often boring: a permission setting, an approval step, a project file, a checklist, a tool you deliberately did not connect.
The boundary test
If something only tells the model what to do, treat it as guidance. If it changes what the model can see, do, remember, check, or escalate, it has crossed into harness territory.
This is less exotic than it first sounds. A lot of people are already using small harnesses without calling them that.
A Custom GPT is a light harness: instructions, knowledge files, capabilities, and sometimes actions connected to outside systems. A ChatGPT Project does a simpler version by grouping chats, reference files, and custom instructions around one piece of work. These are not industrial agent systems, but they still shape what context reaches the model and what capabilities are available.
A Claude Project sits in the same everyday category, with project instructions and project knowledge. If you have created one for a proposal, job search, research topic, or recurring piece of work, you have already done a mild form of harness design. The move was not just “write better words.” It was narrowing the room.
Automation tools make the harness easier to see. Zapier’s Human in the Loop can pause a workflow for human review before continuing. n8n lets builders require human approval before an AI agent executes specific tools. The approval does not depend on the model remembering to be cautious; the workflow stops.
For coding agents, the harness is more visible because the agent has to operate inside a real development environment. Claude Code has tool permissions, hooks, subagents, skills, and MCP connections. GitHub’s Copilot coding agent works in its own development environment, makes changes on a branch, and can open a pull request instead of editing production directly. LangGraph interrupts pause graph execution and wait for external input before continuing. HumanLayer exists almost entirely around this problem: putting approval and oversight around tool calls.
The pattern gets easier to see once you stop looking for one grand product called “a harness.” It is usually a bundle of smaller decisions:
| Harness piece | Real-world control |
|---|---|
| Context | project files, approved sources, uploaded reference docs |
| Tools | search, calendar lookup, email draft, file edit, database lookup |
| Permissions | read-only access, draft-only email, no delete, no deploy |
| State | project notes, task history, saved handoff, checkpoint |
| Checks | citations, tests, review checklist, evaluator, second pass |
| Escalation | approval before send, refund limit, human review queue |
For a writing assistant, the style guide itself is not the harness. It becomes part of the harness if the system loads the relevant rules before drafting, checks factual claims for citations, and blocks publishing until a human approves the draft.
For a research assistant, “use good sources” is not much of a harness. Restricting search to approved sources, requiring every factual claim to include a link, and flagging unsupported claims before the answer is shown gets closer.
For an email assistant, the cleanest harness decision is simple: it can draft, but the final action still goes through you. Reading a calendar is one level of trust. Moving meetings or sending replies is another, and the difference should live in the tool permissions, not in a sentence the model may or may not respect.
So the question shifts. Instead of hunting for the perfect prompt, ask what should sit between this AI and the thing it is about to touch.
Guides and sensors
Fowler and Boeckeler’s most useful split, at least for me, is guides versus sensors.
Guides help before the AI acts: instructions, examples, templates, policies, source documents, style guides, and task descriptions that the harness makes available to the model.
Sensors show up after the AI acts: tests, reviewers, logs, checklists, approvals, citations, comparison steps, and quality checks that the harness runs or records. They answer the less glamorous question: did the work survive contact with reality?

Figure 2. Guides improve the first attempt. Sensors make failures visible enough to feed back into the next attempt.
Most prompt engineering is guide-heavy. It focuses on what to tell the model upfront, which is useful until the model misunderstands the guide, forgets part of it, or buries it under too much context.
Sensors are where the system gets teeth. “Check your work” is a weak prompt if there is nothing to check against. A real checklist, source comparison, test, reviewer, or approval step gives the AI something outside itself to answer to.
Models are often bad judges of their own work. They can explain why an answer is good while missing the actual problem, and confidence in language is not the same thing as proof. AgentBench made the same point from another angle: models that look good in chat can struggle once they have to plan, recover, and act in interactive environments.
A separate check will not make the system perfect. It just puts friction in a place where friction is useful.
More context is not always better
A common instinct with AI is to add more information.
Give it the whole policy document. Give it the full project history. Give it every note. Connect every tool. Add every instruction. Surely, if the AI knows more, it will do better.
The annoying answer is that it depends, and more context can absolutely make things worse.
Chroma’s Context Rot work looked at how models behave as input gets longer. Their finding was uncomfortable: performance can degrade as context grows, even on controlled tasks. The older Lost in the Middle paper showed a related problem: models often performed better when the relevant information was near the beginning or end of a long context, and worse when the useful detail was buried in the middle.

Figure 3. Long context windows are useful, but they do not mean every token receives equal, reliable attention.
The same pattern shows up in coding-agent research. An ETH Zurich preprint on AGENTS.md files reports that repository-level instruction files increased cost, while the performance benefits were mixed. More written guidance was not automatically better guidance.
That matches my own experience. A context file should behave more like a map than a manual. Once it tries to explain everything, the AI has two jobs: do the task and interpret the encyclopedia you handed it.
I keep arguing with myself about this part, because the lazy version of the point is wrong. Sometimes missing context really is the bug, and adding one sentence fixes the output. But context has to earn its place. If a note does not change the next decision the model needs to make, it is probably just fog with better formatting.
More tools can make the agent worse
Tools create a similar trap. Adding one feels harmless. Adding ten changes the shape of the task.
HumanLayer’s post on harness engineering for coding agents makes this point from a practical angle. Every tool gives the model more reach, but it also gives the model one more thing to understand, choose correctly, and use safely.
A tool comes with a name, a description, a permission surface, and a failure mode. After a while the agent is not simply more capable; it is surrounded by more ways to misunderstand the task.
This is why I like the framing in the SWE-agent paper. The authors call the surrounding interface an “agent-computer interface,” and their point is not just that the model needs tools. The interface around the model is not neutral plumbing; it changes what kind of work the agent can reliably do.

Figure 4. More tools can expand what an agent can do, but they also expand the number of choices, failure modes, and permission boundaries the harness has to manage.
If an AI can only read, the blast radius is limited. If it can write, delete, deploy, send, purchase, or change important records, the harness has to do more than politely ask it to be careful. “Never delete important data” is a prompt. Removing delete access is a harness decision.
The AI should not be the only judge
Anthropic’s long-running app development harness is a good technical example. They describe a setup with separate roles: one agent plans, another builds, and another evaluates. They also use written handoffs and context resets so the system does not have to keep everything alive inside one long conversation. The point is not ceremony. It is reducing the chance that one long monologue compounds its own mistakes.
The important part is the separation of jobs. The thing that creates the work should not be the only thing judging the work. We already know this from human teams. The person who wrote the document is not always the best person to proofread it. The person who made the decision may be too attached to the reasoning that got them there.
AI has the same problem, only faster. It can generate an answer and then produce a polished explanation for why that answer is good. Occasionally that explanation catches a real issue. Quite often it just gives the mistake better lighting.
The harness can add a second pass: compare the answer to the source, run the test, ask for a citation, require approval, use a rubric. None of that is glamorous. It is the boring machinery that separates a demo from a workflow you might actually trust.
Start small and let failures teach you
The trap is to design a giant harness before the AI has failed in any meaningful way.
That path leads to huge instruction files, too many connected tools, elaborate approval flows, and a system nobody understands. It looks advanced from far away. Up close, the AI spends half its time navigating scaffolding that may not matter.
A better approach is failure-driven. Start with a small harness, watch where the AI fails, and add the smallest constraint that prevents that specific failure from happening again.
If it keeps using weak sources, limit the sources or require citations. Drafts coming back messy? Add a review checklist. If the goal disappears halfway through, write the goal somewhere persistent. Risky actions happening too quickly need an approval step, not a sterner reminder. When the same mistake repeats, create a check for that mistake.
The harness should feel like it accumulated scars from real use, not decorations from an architecture diagram.
Prompting still matters
Prompts are not useless. A good prompt still matters, and so do clear task framing, examples, and context when it is short and relevant.
The problem is asking prompts to carry the whole system. If an instruction says “do not send without approval” while the AI can still send, the setup is weak. If it says “use reliable sources” but nothing checks the sources, same problem. This is not just a wording problem. It is an interface problem.
The shift is to stop treating AI performance as something the prompt can fix alone.
What to check before rewriting the prompt
Before rewriting the instruction again, look at the setup around it:
- What can the AI see, and what should stay out of view?
- Which tools can it call, and which actions should be impossible?
- What state should live outside the chat so the model does not have to remember everything?
- What does correctness get checked against: sources, tests, rubrics, reviewers, or approvals?
- What gets logged so you can understand what happened later?
- Where should the AI stop and ask a person to decide?
Those questions are less exciting than prompt tricks, but asking these questions can get you one step closer to making AI usable for serious work…
Sources
Core framing:
- Martin Fowler: Harness engineering for coding agent users
- Anthropic: Harness design for long-running application development
- HumanLayer: Skill Issue: Harness Engineering for Coding Agents
- OpenAI: Harness engineering: leveraging Codex in an agent-first world
Real examples and nearby products:
- OpenAI Help: Creating and editing GPTs
- OpenAI Developers: GPT Actions
- OpenAI Help: Projects in ChatGPT
- Anthropic Help: Claude project visibility, knowledge, and instructions
- Anthropic Docs: Claude Code hooks
- Anthropic Docs: Claude Code settings and permissions
- GitHub Docs: About GitHub Copilot coding agent
- GitHub Docs: Configure the Copilot coding agent environment
- Zapier Help: Human in the Loop
- n8n Docs: Human-in-the-loop for AI tool calls
- LangGraph Docs: Interrupts
- LangGraph Docs: Human-in-the-loop
Research and caution: